

Questo articolo è il secondo di una serie di approfondimenti dedicati al Machine Learning, la branca dell'intelligenza artificiale che si pone come obiettivo quello di sviluppare sistemi che consentano ai sistemi computazionali (computer, robot, software, etc.) di apprendere e svolgere azioni ed attività in modo simile a quello degli esseri umani o animali, ovvero imparando dall'esperienza.
In questo contributo ci dedicheremo ad approfondire il "framing", ovvero l'inquadramento di un tipico problema risolvibile con tecniche di Machine Learning: ci occuperemo dunque di illustrare le principali tecniche messe a disposizione da questo approccio per inquadrare un problema nel modo corretto e scomporlo nei suoi elementi chiave utilizzando i termini di uso comune.
Machine Learning e predictive modeling
Prima di addentrarci nella definizione dei suoi elementi chiave, è necessario spendere qualche parola sui principali ordini di problemi che il Machine Learning consente di affrontare in modo efficace. Si tratta di una premessa estremamente importante, poiché il tipo di problema che intendiamo risolvere determinerà non solo l'effettiva utilità di adottare tale approccio metodologico, ma anche l'eventuale scelta del modello di auto-apprendimento da utilizzare.
Senza timore di generalizzare, possiamo affermare che le tecnologie di Machine Learning sono efficaci in tutti i casi in cui vogliamo effettuare delle previsioni utilizzando l'esperienza fornitaci da una serie storica di dati noti (labeled examples) al fine di determinare possibili risultati futuri (unlabeled examples): in altre parole, il Machine Learning è utile quando abbiamo necessità di risolvere problemi mediante tecniche e metodologie basate sull'analisi predittiva.
Questo concetto è alla base del predictive modeling, una tecnica che prevede la soluzione di un problema attraverso un procedimento matematico di approssimazione di una funzione di mapping (F) che utilizzi una o più variabili di input (x) per calcolare il valore di una o più variabili di output (y). Lo scopo del modello è dunque quello di trovare la migliore funzione di mapping possibile, ovvero quella che consenta di le approssimazioni più precise, sulla base del tempo e delle risorse disponibili.
Regression vs Classification
Ovviamente, le tecniche di approssimazione da utilizzare (e quindi le tipologie di modello da applicare) variano a seconda del compito che intendiamo svolgere, ovvero dell'esigenza di approssimazione relativa agli scopi che abbiamo l'obiettivo di soddisfare: è infatti evidente come una app di riconoscimento facciale abbia bisogno di funzioni di mapping molto diverse da quelle utilizzate da uno strumento di misurazione del gradimento degli utenti o da quelle di un filtro antispam.
Le principali esigenze di approssimazione ad oggi note possono essere suddivise in due macro-categorie: regressione e classificazione.
- Le esigenze di regressione, alla base del regression predictive modeling, sono quelle che richiedono la previsione di output continui: in altre parole, numeri o percentuali. Appartengono a questa categoria i modelli che rispondono alle seguenti domande:
- Quale sarà il valore della mia casa tra 20 anni?
- Quante probabilità ci sono che un utente faccia click su questo banner?
- Le esigenze di classificazione, alla base del classification predictive modeling, sono che puntano a prevedere output discreti: in altre parole, suddivisioni per tipologie. Appartengono a questa categoria i modelli che rispondono alle seguenti domande:
- Quale animale raffigura questa immagine?
- Qual è l'argomento di questo messaggio e-mail?
Come si può vedere si tratta di esigenze diverse, che con tutta probabilità richiederanno l'adozione di diverse funzioni di mapping e, soprattutto, diversi criteri per il calcolo della precisione, dell'affidabilità e della capacità predittiva del modello: tuttavia, esistono diversi casi in cui i medesimi algoritmi possono essere utilizzati per soddisfare esigenze appartenenti a categorie diverse. Ad esempio, un problema di classificazione potrebbe essere risolto mediante l'adozione di un modello che preveda la previsione di valori continui, sotto forma di percentuali di probabilità che ciascun dato appartenga a una determinata tipologia (scegliendo poi quella avente percentuale maggiore).
Obiettivi
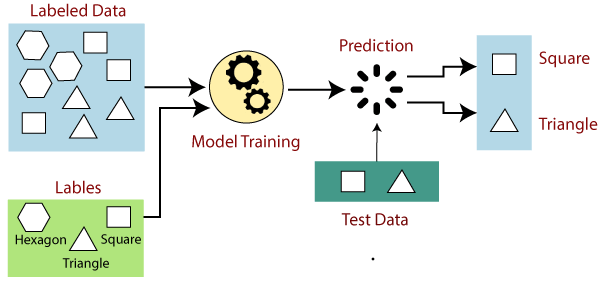
Ora che abbiamo definito il perimetro generale proviamo a mettere a fuoco l'obiettivo di un progetto di Machine Learning, ovvero l'output che puntiamo ad ottenere: senza timore di generalizzare, potremmo definire questo output come una "previsione" (o una serie di previsioni) calcolata sulla base dei dati raccolti, e costantemente "raffinata" sulla base di dati ulteriori inseriti nel sistema nel corso del tempo e opportunamente "metabolizzati" dalle tecniche di auto-apprendimento del sistema stesso. Questa definizione è particolarmente azzeccata nei framework che adottano la tecnica del supervised machine learning (come ad esempio TensorFlow), che consiste nella "deduzione" di un modello predittivo che viene prodotto e "raffinato" analizzando una serie di dati di addestramento (training data) contenenti gli input che ci interessa misurare (features) e nei quali il risultato della previsione (label) sia già noto; la validità del modello così ottenuto potrà essere misurata utilizzandola su ulteriori dati di cui si conosce già il risultato (test data). Nel momento in cui il test viene "superato", ovvero il modello riesce a produrre risultati analoghi alle label già note e presenti nei test data, sarà possibile adottarlo su nuovi set di dati di cui non si conosce il risultato.
Definizioni
Sulla base di quanto appena detto, proviamo ad approfondire i termini finora utilizzati adottando le seguenti definizioni:
- Label. Nota anche come etichetta, la label rappresenta ciò che il modello si pone l'obiettivo di prevedere: la variabile y nella regressione lineare semplice. In un modello di facial recognition la label potrebbe dunque essere il nome della persona raffigurata in un'immagine, mentre in un modello che effettua previsioni sul gradimento di contenuti multimediali potrebbe essere il prossimo video consigliato all'utente ("se ti è piaciuto questo, allora potrebbe piacerti anche..."); in un filtro antispam la label è la categorizzazione del messaggio come "spam" o "non spam"; e così via.
- Features. Note anche come caratteristiche, le feature sono le variabili di input utilizzate per effettuare la previsione: la variabile x nella regressione lineare semplice. Riprendendo l'esempio precedente, in un modello di riconoscimento facciale potremmo considerare feature le caratteristiche somatiche inferibili dai pixel delle singole foto da analizzare, così come gli eventuali meta-tag (nome, data, descrizione, dati sulla posizione geografica, etc.) e altri aspetti che potrebbero aiutare il modello nell'identificazione della persona; in un modello volto a misurare il gradimento di contenuti, le feature potrebbero essere i voti (rating) forniti da altri utenti, magari corredati da altre caratteristiche rilevanti (età, genere, etc); in un filtro antispam, le feature saranno con tutta probabilità le parole contenute nell'oggetto e nel testo dell'email, la resenza/assenza di eventuali link, e così via.
- Training data. Si tratta dei dati che vengono forniti al modello nel corso del processo di addestramento, utilizzati per produrre le logiche inferenziali che, partendo dall'analisi delle feature, portano alla corretta previsione della label: costituisono dunque il carburante principale del processo di auto-apprendimento su cui si basa il Machine Learning.
- Test data. Si tratta di dati in tutto e per tutto simili ai training data, che vengono forniti all'algoritmo al termine dell'apprendimento al fine di misurarne la precisione, l'affidabilità e le capacità predittive. Nella maggior parte dei casi i test data sono un sottoinsieme dei training data estratto mediante apposite tecniche di sub-sampling di cui parleremo in seguito.
- Example. Nome dato a ciascuna singola unità appartenente a un set di dati. Gli example vengono comunemente divisi in due categorie principali:
- Labeled examples, quando l'example include sia le feature (input) che la label (output): si tratta dunque delle singole istanze contenute nei set di training data, utilizzati quindi per l'apprendimento del modello, ma anche di quelli contenuti nei test data, utilizzati dopo la fase di training al fine di verificare l'efficacia del modello.
- Unlabeled examples, quando l'example include le feature ma non le label, che vanno dunque determinate: si tratta delle istanze contenute nei set di dati che vengono inviati al modello al fine di effettuare le previsioni.
- Model. Noto anche come modello, è il meccanismo che definisce la relazione tra le caratteristiche e l'etichetta. Ad esempio, un modello di rilevamento dello spam potrebbe associare fortemente determinate feature presenti in ciascun example (ad es. la presenza dibad words o link a siti sospetti) allo "spam". Il ciclo di vita di ciascun modello è tipicamente composto da due fasi principali:
- Training, nella quale il modello viene costruito e allenato mediante l'utilizzo di un considerevole quantitativo di training data. Questo processo consiste nella presentazione al modello di una serie di labeled examples, con l'obiettivo di fargli apprendere il sistema di relazioni che lega le feature e le label e le operazioni da effettuare per poter determinare (o prevedere) le seconde a partire dalle prime.
- Inference, nella quale il modello viene applicato a una serie di unlabeled examples, ovvero dati dall'output non ancora noto al fine di ottenere previsioni utili.
Conclusione
Per il momento è opportuno fermarci qui: nei prossimi articoli vedremo come è possibile tradurre i termini e le definizioni che abbiamo introdotto in questo approfondimento in termini pratici, introducendo il concetto di regressione lineare e approfondendo gli aspetti legati al training del modello, con particolare riguardo alle tecniche per la riduzione degli scostamenti (empirical risk minimization) e per il calcolo degli errori (Squared Loss e Mean Square Error).
Articoli correlati
- INTELLIGENZA ARTIFICIALE
- MACHINE LEARNING
